Abstract
Many robotic systems, such as mobile manipulators or quadrotors, cannot be equipped with high-end GPUs due to space, weight, and power constraints. These constraints prevent these systems from leveraging recent developments in visuomotor policy architectures that require high-end GPUs to achieve fast policy inference. In this paper, we propose Consistency Policy, a faster and similarly powerful alternative to Diffusion Policy for learning visuomotor robot control.
By virtue of its fast inference speed, Consistency Policy can enable low latency decision making in resource-constrained robotic setups. A Consistency Policy is distilled from a pretrained Diffusion Policy by enforcing self-consistency along the Diffusion Policy's learned trajectories. We compare Consistency Policy with Diffusion Policy and other related speed-up methods across 6 simulation tasks as well as two real-world tasks in which we demonstrate inference on a laptop GPU. For all these tasks, Consistency Policy speeds up inference by an order of magnitude compared to the fastest alternative method and maintains competitive success rates.
We also show that the Conistency Policy training procedure is robust to the pretrained Diffusion Policy's quality, a useful result that helps practioners avoid extensive testing of the pretrained model. Key design decisions that enabled this performance are the choice of consistency objective, reduced initial sample variance, and the choice of preset chaining steps.
Real World Experiments
Trash Clean Up
Consistency Policy
Diffusion Policy
Plug Insertion
Consistency Policy
Diffusion Policy
Simulation experiments
We test 6 different simulation tasks across the Robomimic, Franka Kitchen, and Push-T benchmarks. We compare Consistency Policy with Diffusion Policy and other related speed-up methods.
Methods
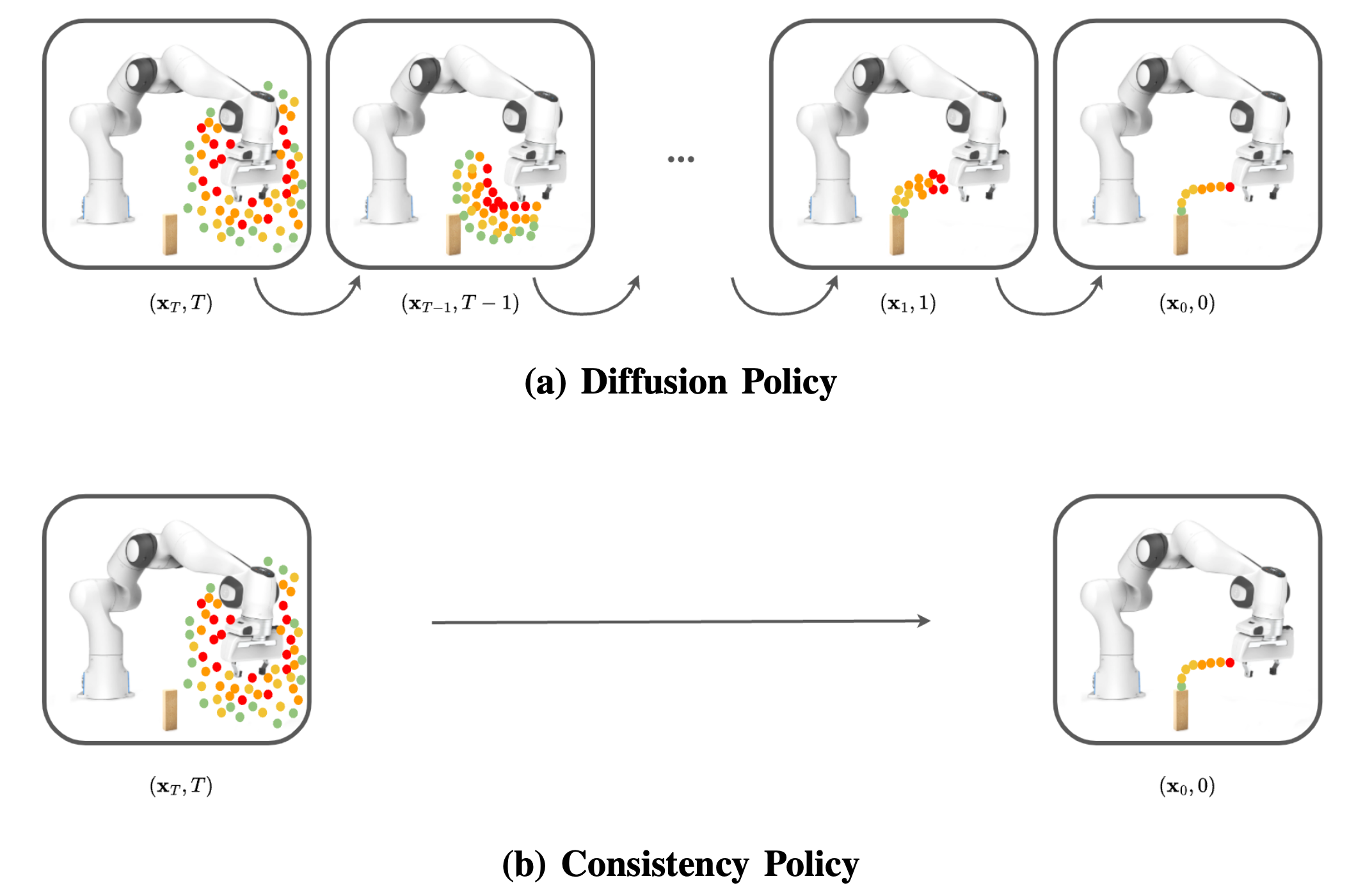
Both Diffusion and Consistency Policy work by sampling random actions and denoising them into action predictions. Diffusion Policy denoises an action sequence over many steps, resulting in high inference costs. Consistency Policy generates an action sequence in a single step.
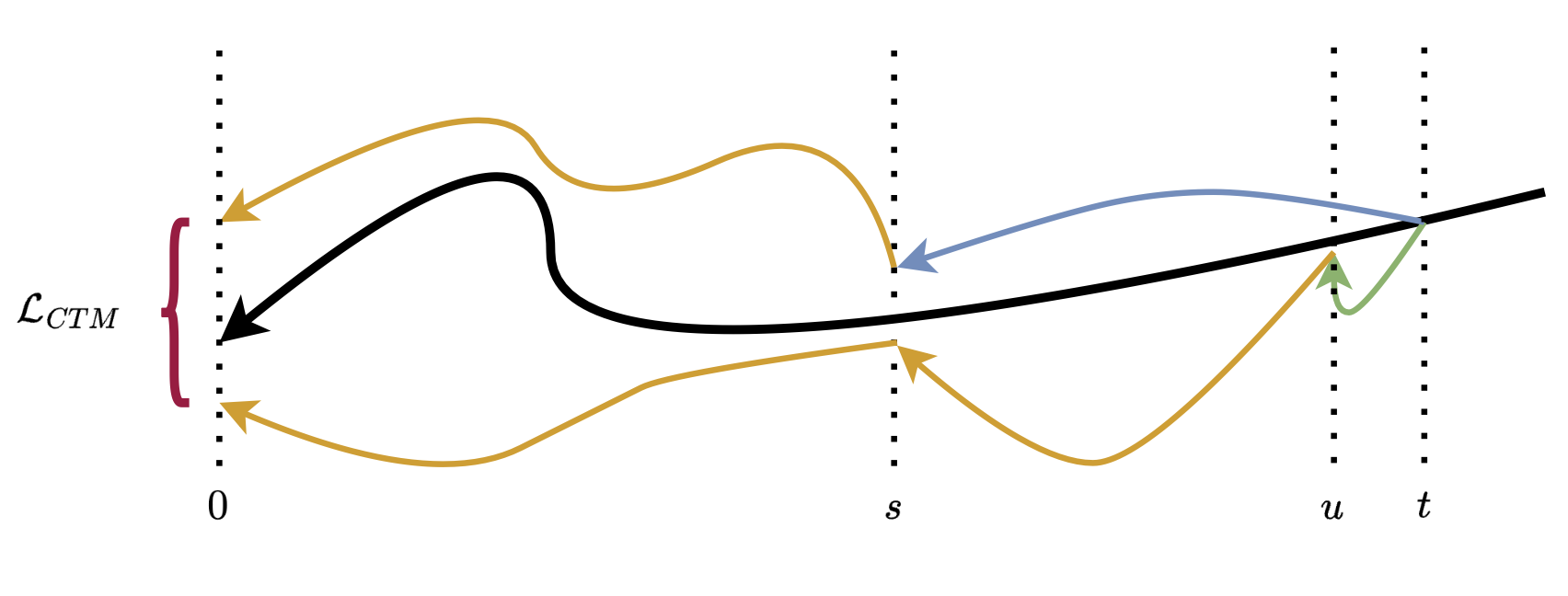
We distill with the CTM objective, which enforces self-consistency along a PFODE (black) by sampling points s, u, t in time, denoising from t → u with a teacher model under stopgrad (green), denoising from t → s with the student model (blue), and denoising u → s with the student model under stopgrad (orange). We then use the stopgrad student model to take both generated positions at time s back to time 0. The difference between these two final generations is the computed loss, LCTM (red).
In our experiments, we found u = t − 1 and s arbitrary below u to work best.
BibTeX
@inproceedings{prasad2024consistency,
title = {Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation},
author = {Prasad, Aaditya and Lin, Kevin and Wu, Jimmy and Zhou, Linqi and Bohg, Jeannette},
booktitle = {Robotics: Science and Systems},
year = {2024},
}
Acknowledgements
This work was supported in part by the Toyota Research Institute, and was completed at IPRL lab. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsers.
Contact
If you have any questions, please feel free to contact Aaditya Prasad.